

There's a lot more to Chaos Engineering than just server failure. Learn how to create serverless chaos with application level fault injection.
What is Serverless?
Amazon Web Services provides a service called Lambda. Lambda is often described as a serverless architecture because we are only uploading a single function, not an entire application; as a result, we do not need to provision or manage servers. Instead, we upload our program code as individual functions to Lambda. The functions only show up to execute when they are called and they disappear when their task is complete. We pay only for the compute time we use, instead of deploying services or modules to a provisioned always-on cloud server instance.
What Can I Do With Serverless?
In serverless settings like this, multiple programming languages are supported and the services are scalable, highly available, adaptable to varying load levels, and are seeing adoption across a variety of use cases within a wider application architecture. Some companies are starting to use Lambda and similar platforms to support offerings like mobile gaming because of their flexibility to varying load levels, for sending events to Slack or Datadog, for background tasks that run on a timer, and more. At Gremlin, we use Lambda for our Slack integration to post updates when we run attacks.
Engineering for Reliability
Engineering for reliability in this serverless context involves digging deeper into our application to find ways to inject failure at the application level. We look for places in the code, the subroutines that are potential points of failure and think about what might be impacted. Each callable unit of code has the potential to fail.
Serverless programming involves using more platform capabilities and third-party tools than servers. By choosing to go serverless, we intentionally give up control over many of our dependencies and their availability. Our code can fail due to a slowdown or an inability to communicate with or use these dependencies, and they are outside of our control to fix.
These are things we must plan for and mitigate against and then test with chaos experiments. The various intermediary services provided by any vendor, those components that lie between our functional code and the server, are not infallible.
What happens if an API gateway goes down or a streaming data service like Kinesis stops working? Will our overall application fail or have we built in system reliability to account for that failure? We must plan for these.
Even though the infrastructure is abstracted away and someone else controls it, our code can (and will) fail, because we still have dependencies, bugs that appear unexpectedly, and so on. We still have a variety of failure modes to consider and plan for if we want to create reliable software and robust systems.
Chaos Engineering Differences in Serverless
Traditionally, Chaos Engineering has focused on infrastructure, such as how Chaos Monkey would terminate one or more random cloud instances in a distributed system to help us learn about how well our system responds and whether our automated mitigation schemes are working. This and similar tools like Chaos Gorilla from Netflix’s Simian Army, which simulates the outage of an entire AWS availability zone, seem to be obsolete in a serverless world. Is Chaos Engineering still necessary, and if so, how can it be implemented?
Servers are easier to inspect because you have full access to the server for thread dumps, CPU flamegraphs, access logs, memory dumps, and so on. The downside is that we don’t have a choice, we must dig into these frequently to create and manage working software and keep it working.
Serverless is much less observable. By default, we can only see what it is doing by observing the output of your deployed function, just like with functional programming. The benefit is that there are fewer things for us to concern ourselves with.
With serverless, we have fewer configuration options to handle, frequently as few as two like memory and timeout. On the other hand, we have other configurations available such as identity and access management (IAM) permissions and timeouts, and therefore more opportunities for misconfiguration.
We must also consider that unlike other cloud practices like containers and container orchestration with Kubernetes, serverless functions do not have a server running all of the time in our system. In those designs, you will have some degree of latency associated with autoscaling, depending on your configuration. However, with serverless we will always have some latency when the function is executed while the server “wakes up” as a result of an event-based trigger. We’re also going to have some inherent latency because of how state is dealt with.
By design, serverless function-based designs are locally stateless; the function is called, spun up, processes its input, provides an output, and spins down. So, for things like authentication, nothing is stored locally and a call must be made from the function to another function or service every time a state-related request is made. More latency potential.
Sure, we no longer have to concern ourselves with things like memory leaks, full disks, CPU spikes, out of sync system clocks, processes being killed, and so on because these are now the responsibility of the cloud provider on which we are running our function. But, we do have to manage our connections to other tools.
We are still making network calls, for example using HTTP, DynamoDB, Aurora Serverless, and so on. We need to understand what happens when these services go down or are slowed. Do we handle the error appropriately? Do we get alerted? How much do we get billed?
Observability in serverless is hard and so we do our best to set metrics that help us understand as much as possible about the runtime behavior we inject. We also want to find ways to inject similarly useful types of failure by decorating a request with failure. Here are some ideas:
- We can test our functions by injecting failure with attributes like CustomerID or device types.
- We can inject latency in responses from specific functions or microservices or even trigger response failures. What does a microservice do when the components around it fail? How does a function respond if the identity service disappears?
- We can design controlled experiments surrounding latency timeout tuning, error handling, failbacks and failover, as well as injecting errors into our functions.
More Ideas
This type of thinking opens up new avenues for how precisely we can think about our failure experiments. If we can target a single type of request, we can target only certain device types, only certain users, or only one specific user. This provides us a lot of power and control over our blast radius when designing experiments.
Another idea is that we can use a Lambda instance to post attack events to a messaging service like Slack:
- Our EC2 server generates an SNS message per event, which would get sent to a Lambda.
- The Lambda does a database lookup to find where to send the message payload and then makes an HTTP call to the message service API.
Doing this means that our API server has zero dependencies on the messaging API and is completely unaffected when that messaging service has issues. You could set up tests that show what happens when the messaging service:
- Fails for a single company
- Gets slow for a single company
- Fails completely
Creating Reliability
As we consider how we are going to conduct Chaos Engineering experiments in our serverless architecture, remember that the principles are all about creating reliability. We want our functions to continue to process data streams even when the timestamps differ across the various deployed parts of our total infrastructure. We want customers and users to be able to access the application and use it successfully no matter what is happening behind the scenes.
The goal of Gremlin’s Application Level Fault Injection (ALFI) is to provide an easier way for site reliability engineers and chaos engineers to do failure testing at the application level by inserting breakpoints into the code itself. This offers a more nuanced control over failures and, with serverless architecture, provides a way to test our architecture and our functions without any requirement that we have access to the underlying infrastructure. ALFI also works across multiple function-based providers including not only AWS Lambda, but also Google Cloud Functions and Microsoft Azure Functions.
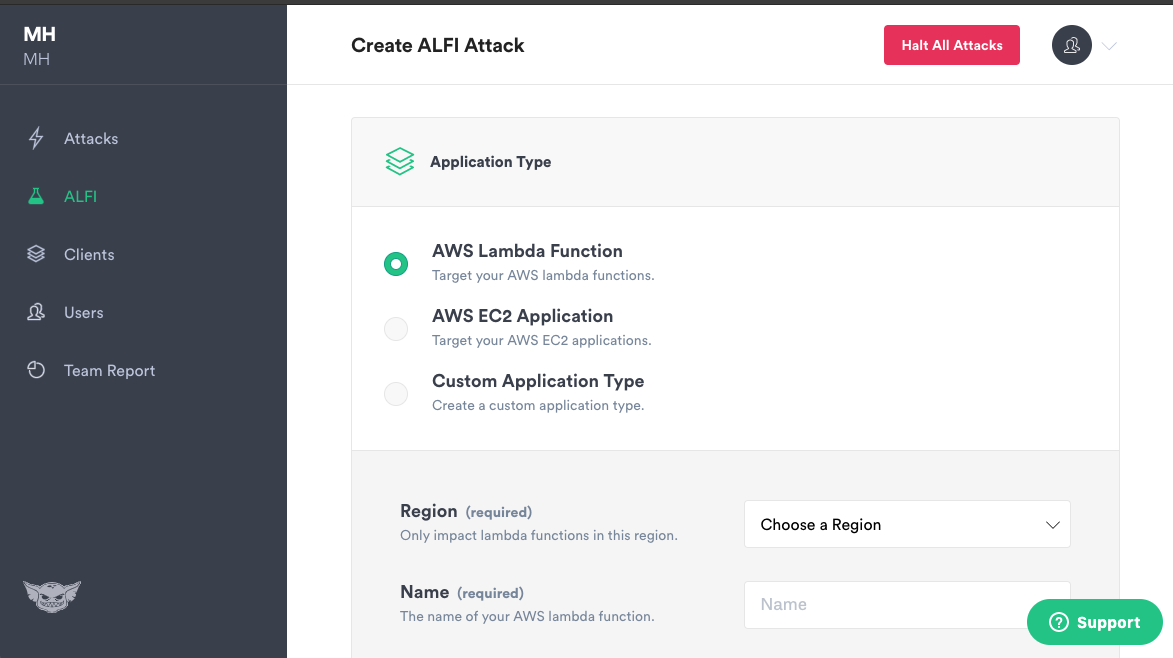
We can use Gremlin to perform our serverless chaos engineering experiments. We can use some combination of open source tools like Chaos Lambda, which is basically Chaos Monkey for Lambda. If you do, pay attention to how active development is on the project you choose and make sure they are responsive to reported security concerns and bug reports (and consider submitting changes, change requests, bug fixes, and features to the project yourself as you think of useful contributions). We can design our own Chaos Engineering scheme and method for our serverless deployment, perhaps in conjunction with experienced engineers we meet at local user groups. In any case, we must be proactive if we want to be as certain as possible that our application is resilient to the inherent failures that will and do occur in any complex system.
Chaos Engineering is not a niche practice exclusively for FANG companies (Facebook, Amazon, Netflix, Google, and similarly large, cloud-based companies), but is something that everyone who is migrating to a more distributed architecture must engage with. Don’t try to shoehorn Chaos Engineering into your spare time. It must be something we plan and schedule, especially as our systems become more and more complex and environments evolve to add new ways to deploy our code.
