
August 22, 2019
Incremental Reliability Improvement


Getting to the Next Nine of Availability
If you improved reliability by just 1% each day, how long would it take for you to get that “extra 9”? That’s an interesting question. This article begins by exploring the potential for small improvements to add up like compound interest. It concludes with a list of practical steps we can take that improve system reliability.
Reliability is how well you can trust that a system will remain available. It is typically expressed as availability and quantified using a percentage of uptime in a given year. We care because we often have service level agreements (SLAs) that refer to monthly or yearly downtime in customer contracts. Downtime costs us money. Uptime rewards us with happy customers and decreased expenses (not to mention fewer pager calls and happier Site Reliability Engineers and DevOps teams).
Nines of Uptime and Availability
A site that achieves 99% availability sounds pretty good at first until you realize that 1% downtime equates to 3.65 days of unavailability in a year. Three nines (99.9%) availability computes to 8.77 hours of downtime in a year. For my personal blog, that is fine. For an e-commerce site that relies on customers being able to spend money as they buy things, even that amount of downtime can become expensive quickly.
Today, forward-looking companies strive for high availability (HA), meaning four nines (99.99%, 52.6 minutes of downtime a year) and even five nines (99.999%, 5.26 minutes of downtime) availability. Some even aim for zero downtime, which is vital in something like an aircraft control system, a communications satellite, or the Global Positioning System (GPS) where any downtime could mean human casualties. How does anyone achieve such reliability?
Stanford University’s Dr. B. J. Fogg proposes that we can improve ourselves immensely over time by making small, incremental, easy changes day by day. Change one small thing a day and watch how it adds up, kind of like compound interest. This aggregation of marginal gains pays big dividends if you persist in pursuing them.
If we improve something by 1% daily (compounding daily), it will be 37 times better in a year (1.01365 = 37.78)! Is this real-life feasible? No, we are not really going to achieve exponential change without limits and math-lovers will correctly note that the equation and curve should illustrate logistic rather than exponential growth. But, this simple idea does illustrate how an intentional active pursuit of small improvements can add up to make a big difference over time.
The corollary is as chilling as that initial assertion was encouraging. If we instead allow that same thing to get just 1% worse daily, the degrading also compounds, like this: 0.99365 = 0.03. By the end of that same year, those minor setbacks that are not dealt with degrade things down to just a statistical difference away from nothing. This matters since we want to avoid drifting into failure and entropy is real with any constantly evolving distributed system.
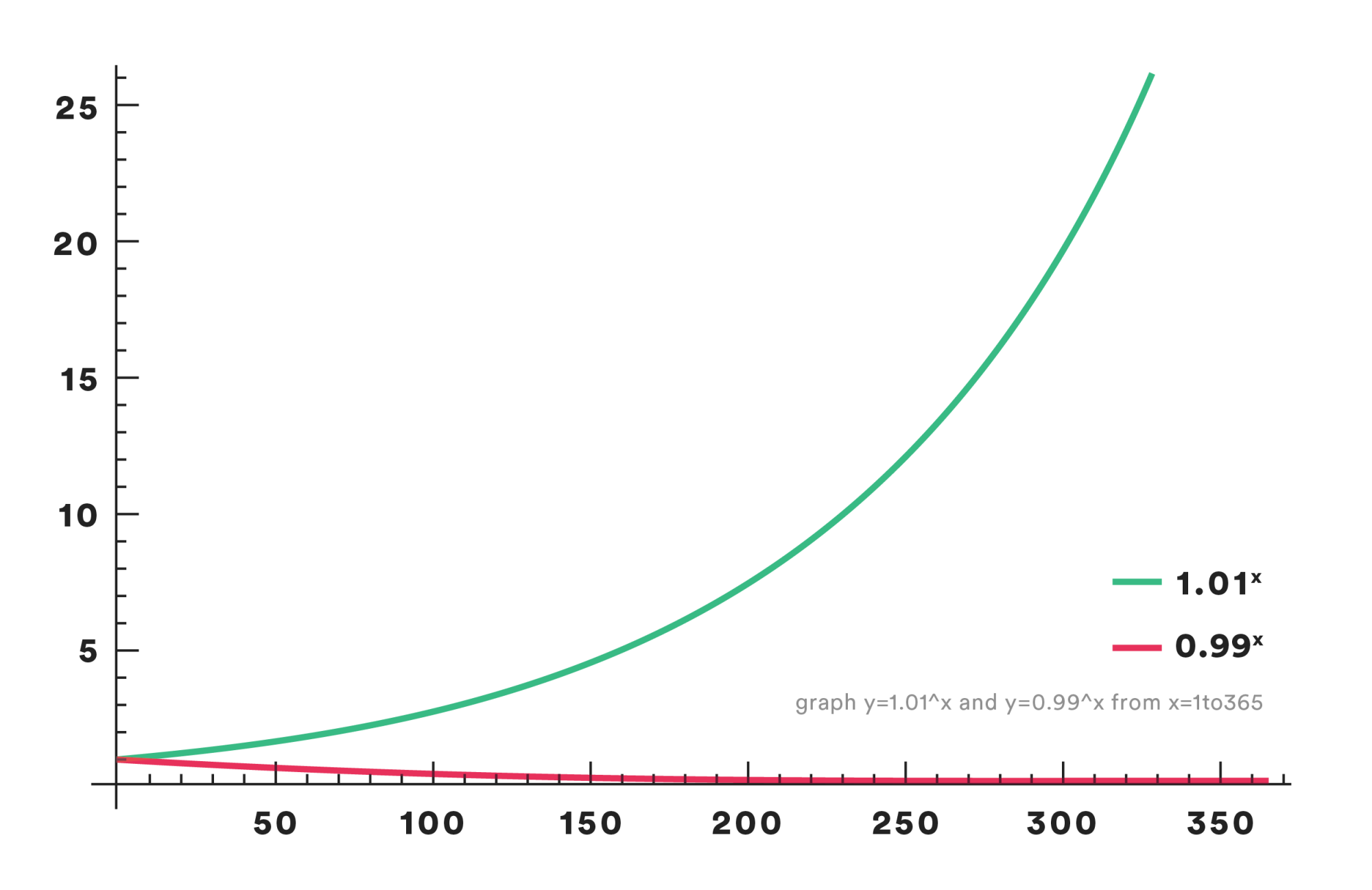
What Does a 1% Improvement in Reliability Look Like?
As we outline some of the major HA requirements, think about small ways you can test and incrementally improve the performance of each within your system. Every one of those small improvements to any component in your system architecture will add up. Make enough small improvements and you will find that you have greatly enhanced your system. Each item listed below starts with a description followed by a short list of ideas that should take an hour or less of your time.
The goal is to understand how the system can accommodate, or be resilient to, potential failures, rather than attempt to isolate one single point of failure.
Create and test runbooks. A runbook (sometimes called a playbook) puts into print important information that is easily forgotten during the brain fog of incident response. They list contact information and responsibilities for all the prime stakeholders and scripts to follow of things to check first and how. Write them down. Keep them updated. Test your playbooks regularly.
- Look for outdated contact information in runbooks and make updates.
- Check the dates when each runbook was last updated and schedule time to review and test any that have not been updated in 3-6 months.
Train teams. Everyone on the team needs a set of shared values and standardized methods. Site Reliability Engineering allows for some diversity in processes, but there are some foundational ideas that must be bought into by all involved for the best result. Take the time to train team members on incident response processes. This will improve how quickly outages are mitigated or fixed. Make sure everyone is familiar with how to communicate and delegate work during an incident.
- Send an email reminder to your team with a list of who to contact during an incident.
- Thank everyone who participated in your most recent incident response training day with an unexpected present on their desk, like a cupcake.
Reduce human intervention in disaster recovery. Every time you experience downtime, once everything is back up and running and the dust has settled, conduct a blameless retrospective. Have everyone involved meet and discuss what happened and why. Take time to discuss, plan, and implement an automated solution so that the next time this problem occurs (and problems often repeat themselves) the mean time between discovery and fix is reduced. See if you can create a mitigation scheme for this single issue that reduces the customer’s perceived downtime to zero.
- Discuss a recent incident with a coworker and write down automation solutions to research further.
- Read through a recent retrospective and schedule automation work for one issue found.
Early maintenance. Perform regular maintenance well before the expected mean time between equipment or software failures. Check the design specifications for hardware you own and operate and make plans for early maintenance and decommissioning before the end of their expected lifespans. Always be migrating to keep things up to date, both for security and for reliability.
- What’s the smallest thing you can migrate over today? Do it.
- What’s the smallest reliability action you can take? Do it.
Migrate to microservices. Consider how you can break up large services into microservices. A microservice is more easily upgraded than larger services. In large systems, you can even replace just one instance of a microservice with a newer version and test it while most of the system still relies on the known-stable previous version. These small and incremental changes enhance overall system reliability despite change-induced failure.
- Look at your most recent architecture diagram. You do update those regularly, right? If not, update it.
- If the diagram is up to date, pick a service that you think may be a good candidate for breaking into smaller microservices and schedule time to research it closely.
Improve launch readiness. How long does it take to deploy a new release version of your application? What are the moving parts? Can any be changed, eliminated, or streamlined? Does every change need to involve a press release or a full marketing push (for sure, some do)? One benefit of moving to a microservices architecture is that you don’t have to wait for every component to be released. You can deploy one microservice multiple times a day while another remains stable over months. New features can be added to a stable application by migrating a small subset of the overall system at a time, perhaps giving the feature to just one client for testing or to one region before rolling out system-wide.
- Make a list all of the required steps for a new release of your software. Schedule time to research each closely to determine why it is or is not a vital part of the process.
- Set a meeting with team members to discuss removing or streamlining one specific step in the release process.
Move to the cloud. Moving to the cloud gives you the ability to define and spin up/down services quickly, across regions and in multiples. What is the smallest thing you can migrate over today? A service? A data store? You don’t have to migrate an entire system at once. You can move to the cloud gradually, starting small and building on each success as you learn from mistakes or difficulties while they are small and easily managed. You can move to containers at the same time, especially to Kubernetes, which makes managing your cloud deployment a little less complicated.
- Read your current architecture diagram and make a list of components you think may be good candidates for hosting in the cloud. Schedule time to research each one more fully.
- Create an account with a company-approved cloud vendor and spend an hour learning how to create and delete a specific type of cloud resource.
Redundancy, redundancy, redundancy. Create multiple instances of any system component that is vital to the system functioning properly. We should do so in a way that anticipates traffic loads and provides more resources than are expected to be needed. We want to do this across multiple regions, so that if an entire region of your cloud provider’s system becomes unavailable our application remains available.
- Test region evacuation with the Blackhole Gremlin to see if the system behaves as we expect. If so, great. If not, you have an opportunity to improve availability, perhaps by reducing recovery times.
- You probably already use a secondary DNS provider rather than relying on just one. If not, schedule the work to get one set up.
- Test what happens in the event of a DNS outage with the DNS Gremlin to confirm that an inability to communicate with one DNS provider does not cripple your system because the second DNS provider is up to the task.
Find monitoring gaps. One of the worst feelings for a Site Reliability Engineer is that pit in the stomach when something goes wrong and we realize we don't have anything set up to detect that issue earlier when it would have been simple to fix and no customer would have been affected. It happens to everyone because not every problem can be predicted. For those, we can predict, think about how you might detect it with your monitoring to reduce mean time to detection (MTTD) and mean time to repair (MTTR). There is a balance here. If you monitor every single thing you think of, you will drown in data and probably miss just as much, so decide what is important to you and focus on that. Run an occasional monitoring GameDay to test and refine your monitoring. Use appropriate monitoring metrics to help you automate and reduce the need for human interaction where appropriate. Gremlin has an integration with Datadog to make this a little easier (and we would be happy to consider integrating with others, if there is a demand).
- Look at every part of your monitoring dashboard(s) and make a list of what you are currently monitoring. Schedule time to meet with team members to look for gaps and to determine whether there are things being monitored unnecessarily.
- Schedule the work to create/remove according to that conversation.
Load balancing, failover, and autoscaling. Load balancing seeks to improve how workloads are distributed across your system resources, such as compute nodes or database instances. Failover automatically switches loads from a non-functioning component to one that is working. Autoscaling spins up additional resources and adds them to your system based on specific performance triggers you set.
- Use the CPU Gremlin to validate autoscaling kicks in and whether new resources are added based on the increased CPU load.
- Use the CPU Gremlin to confirm/learn how workload distribution is adjusted by the load balancer based on CPU load.
- Use the CPU Gremlin to validate failover schemes work as designed.
Model and simulate. Find ways to simulate potential problems before they happen to evaluate the system’s expected reliability, turning theory into tested and known information. Systems will break. Use chaos experiments to test them regularly to find weaknesses in advance to prevent as many failures and pager calls as possible. In addition to suggestions in the previous paragraphs, some failure and problems we can simulate include:
- Host failures, to see how the system responds to missing resources. Test using the Shutdown Gremlin.
- Slow connections, to see how the system responds to network latency. Test using the Latency Gremlin.
- Time outs, to see how the system responds to broken communication. Test using the Packet Loss Gremlin.
Use Gremlin's Reliability Calculator Use Gremlin's reliability calculator to help you find existing issues that are common in enterprise software. This will help you prioritize your efforts.
If you haven’t tested your mitigation schemes, load balancing, or any other reliability-focused effort you have made, you are only hoping it works as designed. Perform focused, blast radius limited chaos experiments to test everything you add. Many of these can be done in under an hour. In addition, you can schedule a time to plan larger experiments and create a GameDay for your team.
With all of the examples in this article, we don’t necessarily have to find big problems. Scheduling work is often a big psychological hurdle. Running a small chaos experiment will teach you something new about your system or confirm what you thought you knew. Incremental improvements in reliability all add up. It may seem trivial to speed up autoscaling resource availability by 1%, but when we add that to modest improvements in load balancing, automated disaster recovery, and other things we find while testing our systems for reliability, system performance, and uptime numbers may radically improve over the course of a year. This makes any potential gain you discover worth pursuing.

